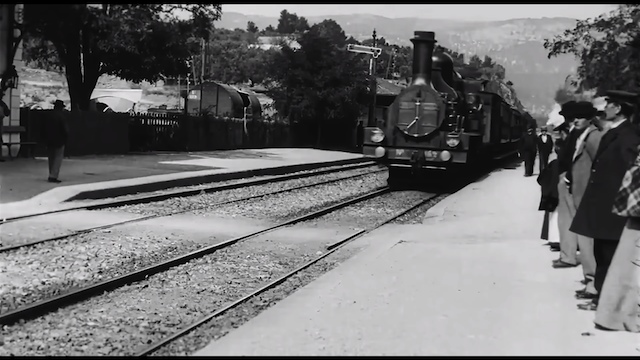
Sempre più ricercatori stanno usando l’intelligenza artificiale per trasformare filmati storici – come l’atterraggio sulla luna dell’Apollo 16 e il film dei fratelli Lumière del 1895 “L’arrivo di un treno alla stazione di La Ciotat” – in video ad alta risoluzione e frame rate che sembrano essere stati girati con attrezzatura moderna. Un grande vantaggio per chi si batte per la conservazione di questi video ma soprattutto, come bonus aggiuntivo, le stesse tecniche potrebbero essere applicate ai filmati per lo screening di sicurezza, la produzione televisiva, il cinema e altri scenari simili.Nel tentativo di semplificare il processo, i ricercatori dell’Università di Rochester, della Northeastern University e della Purdue University, hanno recentemente proposto un framework che genera video al rallentatore ad alta risoluzione da un frame rate basso e video a bassa risoluzione. Dicono che il loro approccio – Space-Time Video Super-Resolution (STVSR) – non solo genera video quantitativamente e qualitativamente migliori rispetto ai metodi esistenti, ma è tre volte più veloce dei precedenti modelli di intelligenza artificiale all’avanguardia.In un certo senso, porta avanti il lavoro pubblicato da Nvidia nel 2018, che descriveva un modello di intelligenza artificiale che poteva applicare il rallentatore a qualsiasi video, indipendentemente dal frame rate. E simili tecniche di aumento della risoluzione sono state applicate nell’ambito dei videogiochi. L’anno scorso, i fan di Final Fantasy hanno utilizzato un software da 100 dollari chiamato AI Gigapixel per migliorare la risoluzione dei fondali di Final Fantasy VII.L’STVSR apprende l’interpolazione temporale (ovvero come sintetizzare i frame video intermedi inesistenti tra i frame originali) e la super-risoluzione spaziale (come ricostruire un frame ad alta risoluzione dal frame di riferimento corrispondente e dai frame di supporto vicini) contemporaneamente. Inoltre, grazie a un modello di memoria a lungo termine convoluzionale associato, è in grado di sfruttare il contesto di un video con un allineamento temporale per ricostruire i fotogrammi dalle funzionalità aggregate.I ricercatori hanno addestrato l’STVSR utilizzando un set di dati di oltre 60.000 clip a 7 frame di Vimeo, con un corpus di valutazione separato suddiviso in set di movimento rapido, medio e lento per misurare le prestazioni in varie condizioni. In alcuni esperimenti, hanno scoperto che STVSR ha ottenuto miglioramenti “significativi” sui video con movimenti rapidi, compresi quelli con movimenti “stimolanti” come i giocatori di basket che scendono in campo. Inoltre, ha dimostrato un’attitudine per la ricostruzione di cornici “visivamente accattivanti” con strutture di immagine più accurate e meno artefatti sfocati, rimanendo allo stesso tempo fino a quattro volte più piccoli e almeno due volte più veloci dei modelli di base.“Con un design così articolato, la nostra rete è in grado di esplorare l’interrelazione tra interpolazione temporale e super-risoluzione spaziale nel compito”, hanno scritto i coautori del documento di prestampa che descrive il lavoro. “Fa valere il nostro modello per imparare in modo adattivo a sfruttare utili contesti temporali locali e globali per alleviare i grandi problemi di movimento. Numerosi esperimenti dimostrano che il nostro framework è più efficace ed efficiente delle reti esistenti”.I ricercatori intendono rilasciare il codice sorgente questa estate.3 marzo 2020
Fonte Fastweb.it